El sesgo de la IA puede surgir de las instrucciones de anotación - TechCrunch
La investigación en el campo del aprendizaje automático y la IA, ahora una tecnología clave en prácticamente todas las industrias y todas las empresas, es demasiado extensa para que alguien la lea en su totalidad. Esta columna, Perceptron (anteriormente Deep Science), tiene como objetivo recopilar algunos de los descubrimientos y artículos recientes más relevantes, particularmente en el campo de la inteligencia artificial, pero no limitado a él, y explicar por qué son importantes.
Esta semana en AI, un nuevo estudio muestra cómo el sesgo, un problema común con los sistemas de IA, puede comenzar con las instrucciones dadas a los reclutas para comentar los datos de los que aprenden los sistemas de IA para hacer predicciones. Los coautores señalan que los anotadores recogen patrones en las instrucciones que hacen que contribuyan con anotaciones, que luego se sobrerrepresentan en los datos, por lo que apuntan al sistema de IA en esas anotaciones.
Muchos sistemas de IA hoy en día "aprenden" a comprender imágenes, videos, textos y audios a partir de ejemplos señalados por los comentaristas. Las etiquetas permiten a los sistemas extrapolar las relaciones entre los ejemplos (p. ej., la asociación entre el encabezado "fregadero de cocina" y una foto de un fregadero de cocina) a datos que los sistemas no han visto previamente (p. ej., fotos de fregaderos de cocina, ninguno no incluido en los datos utilizados para "aprender" el modelo).
Esto funciona notablemente bien. Pero la anotación es un enfoque imperfecto: los anotadores generan sesgos que pueden alimentar el sistema entrenado. Por ejemplo, los estudios han demostrado que es más probable que el anotador promedio etiquete oraciones en inglés vernáculo afroamericano (AAVE, por sus siglas en inglés), la gramática informal utilizada por algunos estadounidenses negros, como tóxicos, lo que lleva a los detectores de toxicidad de IA entrenados en las etiquetas a AAVE visto como desproporcionadamente tóxico.
Resulta que las predisposiciones de los comentaristas pueden no ser las únicas responsables de la presencia de sesgos en las etiquetas de entrenamiento. En un estudio preliminar de la Universidad Estatal de Arizona y el Instituto Allen para IA, los investigadores examinaron si una fuente de sesgo podría estar en las instrucciones escritas por los creadores de conjuntos de datos para servir como guías para los comentaristas. Tales instrucciones suelen incluir una breve descripción de la tarea (por ejemplo, "Etiqueta todas las aves en estas fotos") junto con varios ejemplos.

Autor de la foto: Parmar et al.
Los investigadores examinaron 14 conjuntos de datos de "punto de referencia" diferentes utilizados para medir el rendimiento de los sistemas de procesamiento de lenguaje natural o sistemas de IA que pueden clasificar, resumir, traducir y analizar o manipular texto. Al examinar las instrucciones de tareas dadas a los anotadores que trabajaban en los conjuntos de datos, encontraron evidencia de que las instrucciones hacían que los anotadores siguieran ciertos patrones que luego se pasaban a los conjuntos de datos. Por ejemplo, más de la mitad de las anotaciones en Quoref, un conjunto de datos desarrollado para probar la capacidad de los sistemas de inteligencia artificial para comprender cuándo dos o más términos se refieren a la misma persona (o cosa), comienzan con la oración "¿Cuál es el nombre?". una oración que está presente en un tercio de las declaraciones para el registro.
El fenómeno, que los investigadores denominan "sesgo de instrucción", es de particular preocupación porque sugiere que los sistemas entrenados con datos de anotación/instrucción sesgados pueden no funcionar tan bien como se pensó originalmente. De hecho, los coautores encontraron que el sesgo de instrucción sobreestima el rendimiento de los sistemas y que estos sistemas a menudo no logran generalizar más allá de los patrones de instrucción.
El lado positivo es que se ha descubierto que los sistemas grandes como GPT-3 de OpenAI son generalmente menos sensibles al sesgo de instrucciones. Pero la investigación sirve como un recordatorio de que los sistemas de IA, como los humanos, son propensos a desarrollar sesgos de fuentes que no siempre son obvias. El desafío insuperable es descubrir estas fuentes y mitigar los impactos aguas abajo.
En un artículo menos aleccionador, científicos de Suiza concluyeron que los sistemas de reconocimiento facial no se dejan engañar fácilmente por caras realistas editadas por IA. Los "ataques de transformación", como se les llama, implican el uso de IA para alterar la foto en una tarjeta de identificación, pasaporte u otro documento de identidad para eludir los sistemas de seguridad. Los coautores crearon "morfos" utilizando IA (StyleGAN 2 de Nvidia) y los probaron con cuatro sistemas de reconocimiento facial de última generación. Los Morphs, a pesar de su apariencia real, no representaban una amenaza significativa, afirmaron.
En otra parte del espacio de visión por computadora, los investigadores de Meta han desarrollado un "asistente" de IA que puede recordar las propiedades de un espacio, incluida la ubicación y el contexto de los objetos, para responder preguntas. El trabajo, detallado en un documento preliminar, es probablemente parte de la iniciativa Project Nazare de Meta para desarrollar lentes de realidad aumentada que usan IA para analizar su entorno.
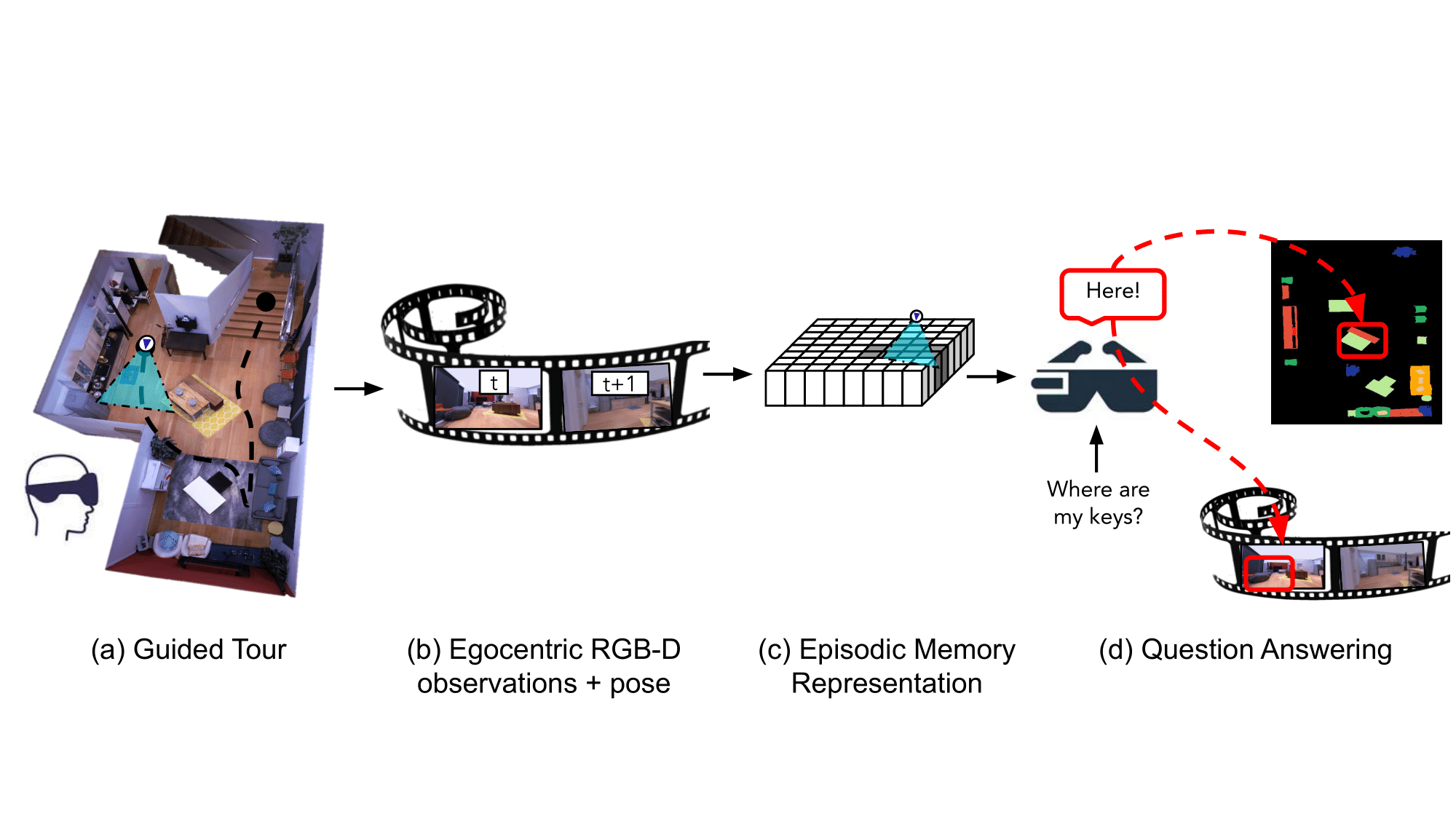
Autor de la foto: Meta
El sistema de los investigadores, diseñado para su uso en cualquier dispositivo corporal equipado con una cámara, analiza imágenes para construir "memorias de escena semánticamente ricas y eficientes" que "codifican información espaciotemporal sobre objetos". El sistema recuerda dónde se encuentran los objetos y cuándo aparecieron en las secuencias de video, y también almacena en su memoria las respuestas a las preguntas que un usuario podría hacer sobre los objetos. Por ejemplo, cuando se le pregunta "¿Dónde vio mis llaves por última vez?", el sistema puede indicar que las llaves estaban en una mesa auxiliar en la sala de estar esa mañana.
Meta, que según se informa planea lanzar gafas AR totalmente funcionales en 2024, telegrafió sus planes para la IA "egocéntrica" en octubre pasado con el lanzamiento de Ego4D, un proyecto de investigación de IA a largo plazo "percepción egocéntrica". La compañía dijo en ese momento que el objetivo era enseñar a los sistemas de inteligencia artificial a comprender las señales sociales, cómo las acciones del usuario de un dispositivo AR podrían afectar su entorno y cómo las manos interactúan con los objetos, entre otras cosas.
Desde el lenguaje y la realidad aumentada hasta los fenómenos físicos, un modelo de IA ha demostrado su utilidad en un estudio del MIT sobre las olas: cómo se rompen y cuándo. Aunque pueda parecer un poco misterioso, la verdad es que los modelos de olas son necesarios tanto para construir estructuras en y cerca del agua como para modelar la interacción del océano y la atmósfera en modelos climáticos.

Autor de la foto: CON
Normalmente, las olas se simulan aproximadamente a través de una serie de ecuaciones, pero los investigadores entrenaron un modelo de aprendizaje automático utilizando cientos de instancias de olas en un tanque de agua de 40 pies lleno de sensores. Al observar las olas y hacer predicciones basadas en evidencia empírica, y luego compararlas con los modelos teóricos, la IA ayudó a mostrar dónde se quedaron cortos los modelos.
La investigación en EPFL se convierte en una startup donde la tesis doctoral de Thibault Asselborn sobre el análisis de escritura a mano se ha transformado en una aplicación educativa completa. Usando algoritmos que desarrolló, la aplicación (llamada School Rebound) puede identificar hábitos y acciones correctivas cuando un niño escribe con un bolígrafo en un iPad en solo 30 segundos. Estos se presentan al niño en forma de juegos que le ayudan a escribir con mayor claridad fortaleciendo los buenos hábitos.
"Nuestro modelo científico y precisión son importantes y nos diferencian de otras aplicaciones existentes", dijo Asselborn en un comunicado de prensa. “Hemos recibido cartas de maestros que han visto a sus alumnos mejorar a pasos agigantados. Algunos estudiantes incluso vienen a practicar antes de la clase”.

Autor de la foto: Universidad de Duke
Otro nuevo hallazgo en las escuelas primarias se refiere a la detección de problemas de audición durante los exámenes de rutina. Estas evaluaciones, que algunos lectores pueden recordar, a menudo usan un dispositivo llamado timpanómetro que debe ser operado por audiólogos capacitados. Si no hay uno disponible, por ejemplo en un distrito escolar remoto, es posible que los niños con problemas de audición no obtengan la ayuda que necesitan de manera oportuna.
Samantha Robler y Susan Emmett de Duke decidieron construir un timpanómetro que esencialmente funcionaría solo, enviando datos a una aplicación de teléfono inteligente donde serían interpretados por un modelo de IA. Cualquier motivo de preocupación se marcará y el niño podrá ser evaluado más a fondo. No sustituye a un experto, pero es mucho mejor que nada y puede ayudar a identificar problemas auditivos mucho antes en lugares sin los recursos adecuados.
Si quieres conocer otros artículos parecidos a El sesgo de la IA puede surgir de las instrucciones de anotación - TechCrunch puedes visitar la categoría Noticias.

Deja una respuesta